
by Jacob Knight
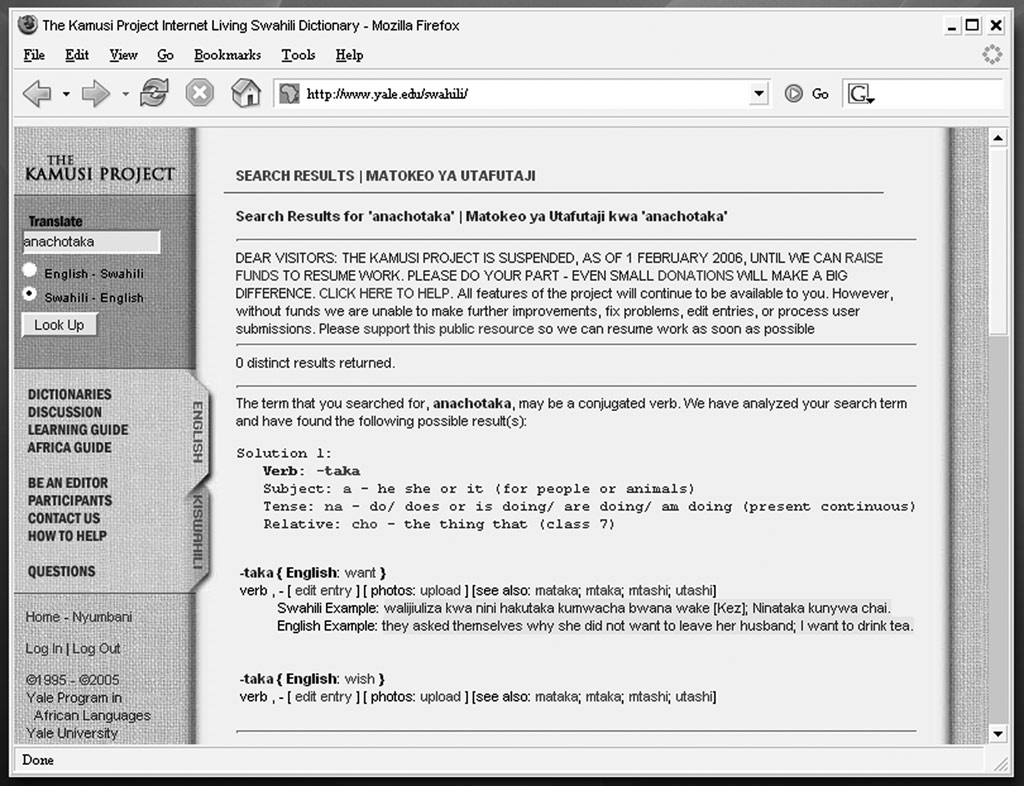 The Kamusi Project website
The Kamusi Project websiteThe Yale University ‘Kamusi Project’ www.yale.edu/swahili/ has hosted an online Kiswahili–English dictionary since 1995. It is a well used resource and a live dictionary which anyone can add new words
to.
However, until now, learners of Kiswahili have had a fundamental difficulty when using any dictionary. In English and other European languages, the end of words may be changed according to the tense etc, but a learner looking to translate say “needed” should be able to find “need” in a dictionary without too many problems. In Kiswahili, however, numerous prefixes and infixes are added to the beginning of words, so to translate say nitaenda the student had to know that this is
from verb -enda before they could look anything up in the dictionary. To translate atakapopigwa they needed to know firstly that this is from verb -pigwa and secondly that it is a passive form of the verb -piga.
Over the last couple of years I have been working in my spare time on a computer programme for an “intelligent” dictionary able to detect the verb from a word entered by the user, and I am gad to say that, with help from the Kamusi editor Martin Benjamin and programmer Andrew Smith, this has now been incorporated into the online dictionary. So now, typing nitaenda into the dictionary brings up a result explaining that this is from verb -enda and giving the meaning.
We believe this is the first time such an “intelligent” dictionary has been created for a Bantu language. For working out the computer code I am indebted to Peter Wilson’s “Simplified Swahili” book with its excellently clear descriptions. A
standard Kiswahili conjugated verb is made up of “Subject prefix – Tense infix – Relative infix – Object infix – Verb stem – Ending”, and the challenge is to extract the verb stem from this. Luckily, Kiswahili is very regular and follows well defined rules which means that this is not quite as bad a problem as might first appear.
The program works by stepping through all possible tenses (43 at the last count!) and tries to match the test word with all legal combinations of subject, object and relative infixes. This typically produces several possible solutions, which are then checked in the dictionary and only those verbs which are found in the dictionary are displayed. For example anakupenda gives 5 initial solutions, the first being a verb -nakupenda in the present continuous tense (which isn’t found in the dictionary and
is therefore rejected), the second verb -kupenda in the present tense with no object (which again is rejected) and the remaining three are the “correct” solution with the verb -penda and object ku – three solutions since ku could represent “you” or “it” (object in noun class 15), or “it” (a place – locative class). An earlier version of the program jumped straight to the -penda solution, but this didn’t work for say anakusanya where the ku is not in fact an object infix and the second solution (verb -kusanya) is actually the “correct” solution.
The subjunctive and other less regular tenses were rather harder to parse and tend to produce more possible solutions. For example the present tense negative siendi could be conjugated from a verb -endi or -enda. However, by checking the solutions in the dictionary, the majority of these “wrong” solutions are eliminated and we were all pleasantly
surprised at how few times a “wrong” solution is generated.
Unfortunately the project has run out of funds so the implementation of the algorithms to detect verbs in the passive state etc are on hold. Please feel free to test the dictionary and if you are able please make a donation
to continue the work.